.png)

はじめに
Stable Diffusionは、画像生成のための強力なAIツールとして知られていますが、ユーザーがモデルをカスタマイズして特定のスタイルやコンテンツに適応させるために「LoRA」(Low-Rank Adaptation)という技術を使用することができます。本記事では、LoRAの基本的な概念と、その導入方法について詳しく解説します。
LoRA(Low-Rank Adaptation)は、AIモデルの学習プロセスを効率化する技術で、特に画像生成モデルの微調整に使用されます。通常、大規模なモデルをトレーニングするには多くの計算リソースと時間が必要ですが、LoRAはこれを大幅に削減します。LoRAは既存のモデルに対して小さな変更を加えることで、特定のスタイルやコンテンツに対応する新しいモデルを迅速に作成することができます。
モデルとLoRAの違い
1. トレーニングの規模とデータ
- モデル: 通常、Stable Diffusionのモデルは大量のデータセットを用いて長期間にわたりトレーニングされます。このプロセスは計算リソースが非常に高く、データセットには何百万もの画像が含まれています。
- LoRA: LoRAは、すでにトレーニングされたモデルに特定の特徴を追加するために使われる軽量な手法です。LoRAは、特定のタスクやスタイルに焦点を当てた少量のデータセットでトレーニングされるため、トレーニングの時間やコストが大幅に削減されます。
2. サイズと運用
- モデル: Stable Diffusionのモデル自体は非常に大きなファイルサイズを持ち、通常は数GBに達します。これにより、運用には高い計算能力とメモリが必要です。
- LoRA: LoRAは、元のモデルに比べて非常に小さなファイル(通常は数十MB程度)です。これにより、同じベースモデルを使用しながらも、異なるスタイルやタスクに簡単に切り替えられます。
3. 適用範囲
- モデル: モデルは広範な用途に対応でき、特定のスタイルやタスクに限らず、一般的な画像生成に使用されます。例えば、風景、ポートレート、抽象画など、幅広いジャンルの画像を生成できます。
- LoRA: LoRAは特定のスタイルやテーマに特化しています。たとえば、特定のアニメスタイルや特定のキャラクターの画像を生成する際にLoRAを使うことで、そのスタイルに合った画像生成が可能になります。
このように、LoRAとモデルはトレーニングの規模やデータ、ファイルサイズ、そして適用範囲において大きな違いがあります。それぞれの特性を理解することで、適切な場面で適切なツールを選択できます。
前提条件
LoRAを導入する前に、以下の条件を確認してください:
- Stable Diffusion WebUI Forge: すでにインストールされ、正常に起動すること。
- LoRAモデルファイル: 使用したいLoRAモデルがすでにダウンロード可能な状態であること。CivitaiやHugging Faceなどから取得できます。
- 基本的な操作スキル: ファイルのダウンロード、コピー、WebUIの設定ができるスキルが必要です。
手順
LoRAモデルの検索
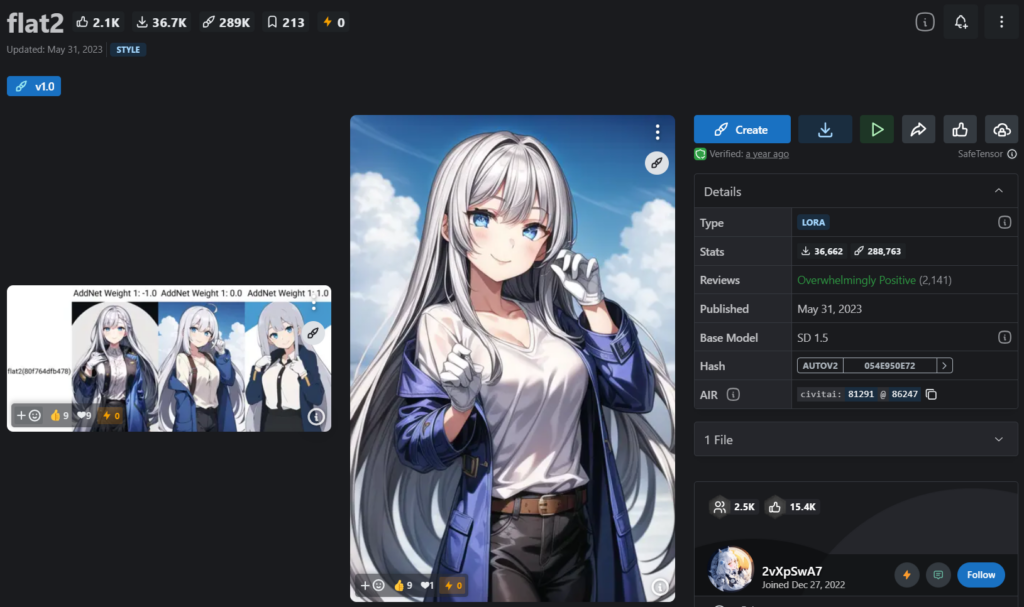
CivitaiやHugging Faceにアクセスし、使用したいLoRAモデルを検索します。検索結果から適切なモデルを選び、モデルページを開きます。モデルページで提供されている.safetensorsまたは.ckpt形式のLoRAファイルをダウンロードします。
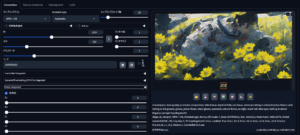
今回はflat2をダウンロードしてみます。適用するとフラットな絵になります。重みをあえてマイナスにして適用することで絵の描きこみが増やすことができます。(「flat1」と比べると、マイナス適用時の絵が明るいです)
構図への影響を抑えたい場合は、拡張機能の「LoRA Block Weight」を使用して調整してください。
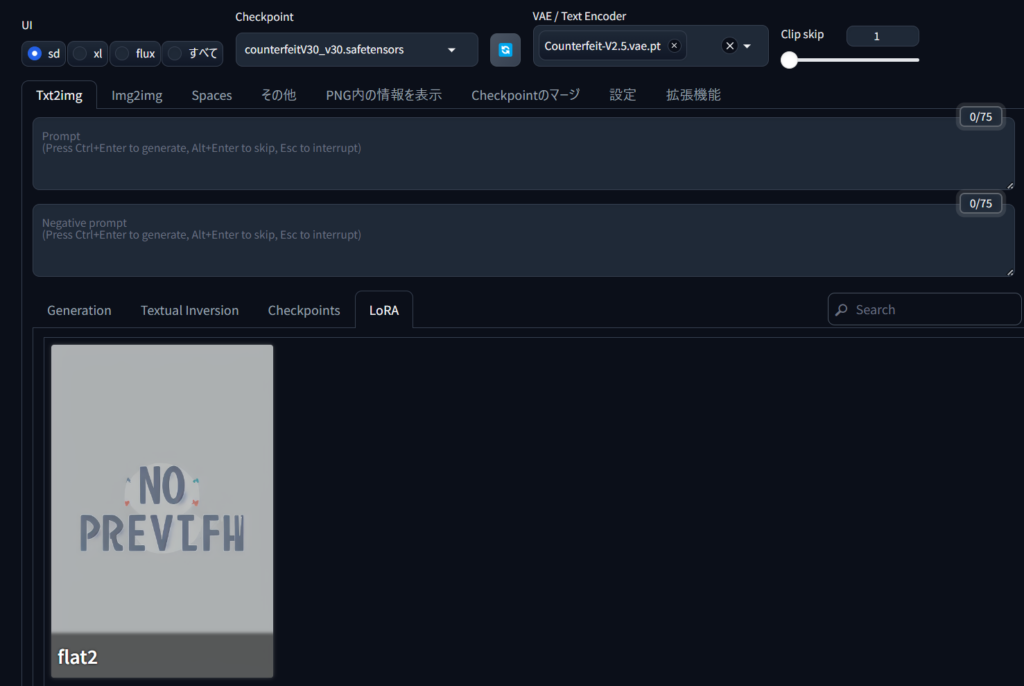
2. LoRAファイルの配置
ファイルのコピー
ダウンロードしたLoRAファイルを、StableDiffusion\stable-diffusion-webui-forge\models\Loraフォルダにコピーします。このフォルダにLoRAファイルを配置することで、WebUIからアクセスできるようになります。

3. WebUIでのLoRA設定
Stable Diffusion WebUI Forgeを開く
WebUIを開きます。

LoRAの選択
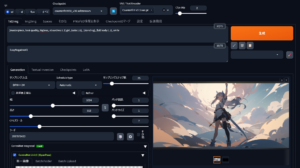
txt2imgやimg2imgタブに移動し、「LoRA」のタブで、導入したLoRAモデルを選択します。選択後、モデルの影響度を調整するスライダーも活用できます。
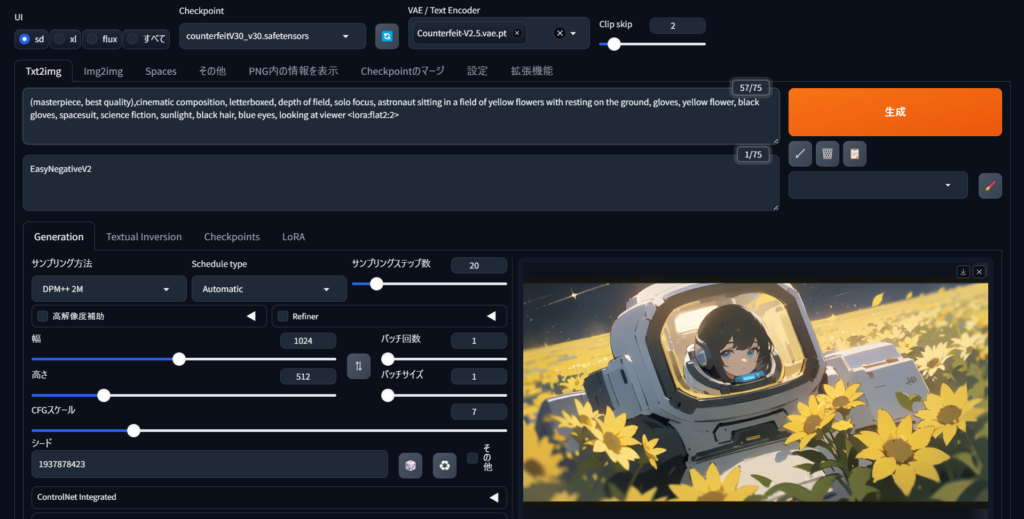
設定の適用と画像生成
LoRAを選択した状態で、通常通りPromptを入力し、画像生成を行います。LoRAの効果により、特定のスタイルやコンテンツに最適化された画像が生成されます。
VAEが設定された状態で、txt2imgやimg2img機能を使用して画像生成を行います。VAEの効果により、生成される画像のディテールや質感がより鮮明になります。



LoRAは、モデルの微調整を簡単に行える強力なツールです。これを活用することで、Stable Diffusion WebUI Forgeをさらにカスタマイズし、あなたのクリエイティブなビジョンを実現することが可能です。LoRAの導入は比較的簡単であり、多様なアートスタイルを探索する絶好の手段です。ぜひ、LoRAを導入して、より豊かな画像生成の世界を楽しんでください。